

Ijraset Journal For Research in Applied Science and Engineering Technology
Predictive Model for Student’s Academic Performance Using Machine Learning Techniques
Authors: Abeer Ali Saeed Amer , Dr. Atef Tayeh Nour El-Din Raslan
DOI Link: https://doi.org/10.22214/ijraset.2024.63659
Certificate: View Certificate
Abstract
This research aims to predict student academic performance using historical data and machine learning algorithms. The dataset includes parental, and academic information about students. The study focuses on three machine learning algorithms: Logistic Regression, Decision Tree, and Support Vector Machine (SVM). To begin, we conducted data analysis to understand the distribution and relationships within the data. Visualizations such as homogeneity analysis of parental education, race, and gender, as well as count plots for gender according to parental education and race, were created to identify patterns and insights. The data was then pre-processed and used to train the three models. Each model\'s performance was evaluated based on accuracy, precision, recall, and F1 score. Confusion matrices and ROC curves were also generated to provide a comprehensive evaluation of each model\'s predictive power. Our results indicate that while the Decision Tree algorithm achieved high accuracy and recall, it showed signs of overfitting. On the other hand, the Logistic Regression model demonstrated a better balance between performance metrics and generalization. Therefore, we recommend the Logistic Regression model for predicting student performance due to its reliability. This research highlights the potential of machine learning in educational data mining and its applicability in improving academic outcomes by identifying students at risk of poor performance early.
Introduction
I. INTRODUCTION
The prediction of student academic performance is a critical area of research in educational data mining, with significant implications for educational institutions, teachers, and students. Accurate predictions can help identify students at risk of underperforming, allowing for support to enhance their academic outcomes. In this study, we aim to use machine learning algorithms to predict student performance based on a range of demographic, parental, and academic factors.
Educational success is influenced by various factors, including background, parental education levels, and individual student characteristics. Traditional methods of assessing student performance often rely on periodic evaluations and examinations, which may not provide a comprehensive picture of a student's potential and challenges. By utilizing historical data and machine learning techniques, we can uncover patterns and predictors of academic success that may not be immediately apparent through traditional methods.
The primary objective of this research is to develop and compare multiple machine learning models to predict student academic performance. Specifically, we aim to analyze and pre-process the dataset to ensure it is suitable for machine learning applications, conduct an exploratory data analysis (EDA) to identify significant patterns and correlations, train and evaluate three machine learning algorithms (Logistic Regression, Decision Tree, and Support Vector Machine), and compare their performance based on accuracy, precision, recall, and F1 score. Finally, we aim to recommend the most suitable model for predicting student performance, considering both predictive power and generalization ability.
The problem we address in this study is the challenge of accurately predicting student academic performance using historical data. Traditional assessment methods may not capture the complexities and nature of student learning and achievement. Machine learning offers a promising alternative, but selecting the appropriate algorithm and ensuring the model's generalization remains a significant challenge.
The main aim of this project is to use machine learning techniques to predict student academic performance accurately. To achieve this, we have set the following specific objectives: develop a robust machine learning model using historical data from a public available dataset, evaluate the model's performance using metrics such as accuracy, precision, recall, and F1 score, utilize standard machine learning algorithms and tools to ensure the feasibility of the project, focus on models that balance predictive accuracy and generalization to avoid overfitting.
II. BACKGROUND
- Educational success is influenced by a multitude of factors, ranging from background and parental education levels to student characteristics and school environments. Traditional methods of assessing student performance, such as periodic evaluations and examinations, often fail to capture the full influences on a student's academic performance.
- Machine learning has demonstrated significant potential in analyzing large datasets to uncover patterns and make predictions. In the context of education, machine learning algorithms can be applied to historical student data to identify predictors of academic success and risk factors for poor performance. This approach allows to improve educational outcomes.
- The use of machine learning in educational data mining is not entirely new, but it remains a rapidly evolving field. Previous studies have explored various factors affecting student performance and have employed different algorithms to predict outcomes. However, there is still a need for comprehensive comparisons of multiple algorithms on diverse datasets to determine the most effective methods for specific educational contexts.
- In this research, we utilize a public dataset from Kaggle that includes demographic, parental, and academic information about students. By applying and comparing three machine learning algorithms—Logistic Regression, Decision Tree, and Support Vector Machine (SVM)—we aim to identify the most effective model for predicting student academic performance. This study contributes to the ongoing exploration of machine learning applications in education, providing insights that could help educators and policymakers develop better strategies for supporting student achievement.
III. METHODOLOGY
This section outlines the steps taken to conduct this research, from data collection and pre-processing to model training and evaluation. The primary goal is to develop and compare multiple machine learning models to predict student academic performance using a dataset from Kaggle.
Figure 4.1 shows the Research Methodology to implement the proposed approach
Refer to figure 4.1.
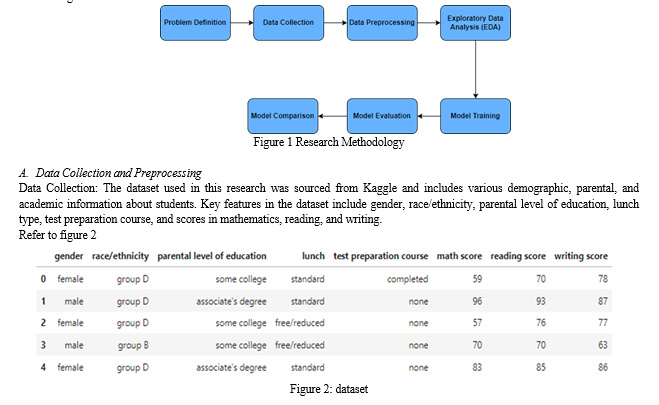



D. Model Evaluation
The performance of the models was evaluated using multiple metrics
- Accuracy: The proportion of correctly classified instances out of the total instances.
- Precision: The proportion of true positive instances out of the total instances predicted as positive.
- Recall: The proportion of true positive instances out of the total actual positive instances.
- F1 Score: The mean of precision and recall, providing a balanced measure of both.
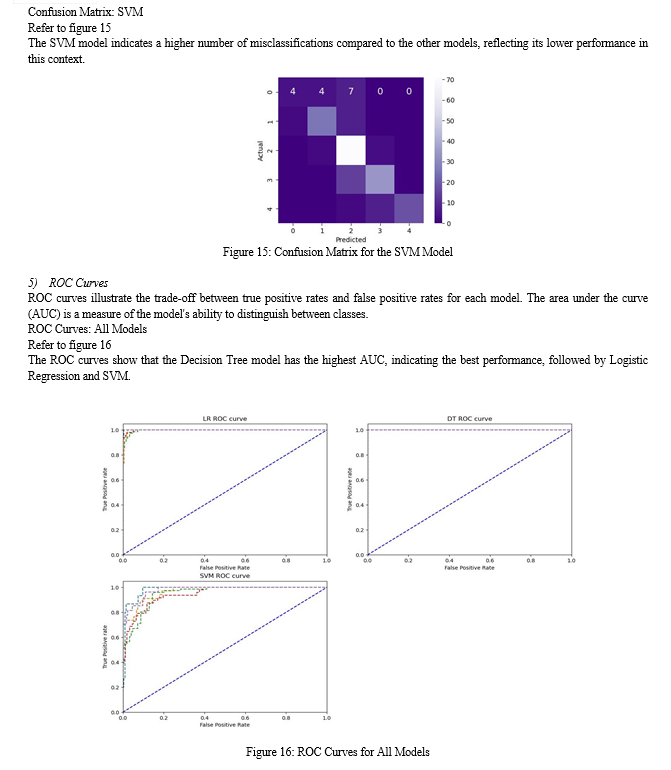
Confusion matrices and ROC curves were also generated to provide a comprehensive evaluation of each model's predictive power.
E. Model Comparison
After training and evaluating the models, their performances were compared based on the evaluation metrics. The model with the highest overall performance and generalization ability was identified as the most suitable for predicting student academic performance.
F. Limitations
- Dataset Limitations: The dataset used may not be representative of the entire student population. It may be limited in terms of geographical diversity, factors, and other demographic variables.
- Feature Limitations: The features available in the dataset might not capture all the factors influencing student performance.
IV. RESULT ANALYSIS AND DISCUSSION
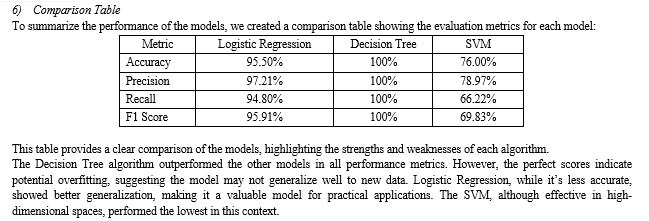
In this section, we analyze the performance of the different machine learning models used in predicting student academic performance. We evaluate the models based on accuracy, precision, recall, and F1 score. Additionally, we discuss the significance of the results and their implications for educational practice.
A. Model Performance Metrics
Three machine learning algorithms—Logistic Regression, Decision Tree, and Support Vector Machine (SVM)—were evaluated using various performance metrics. The key metrics include accuracy, precision, recall, and F1 score.
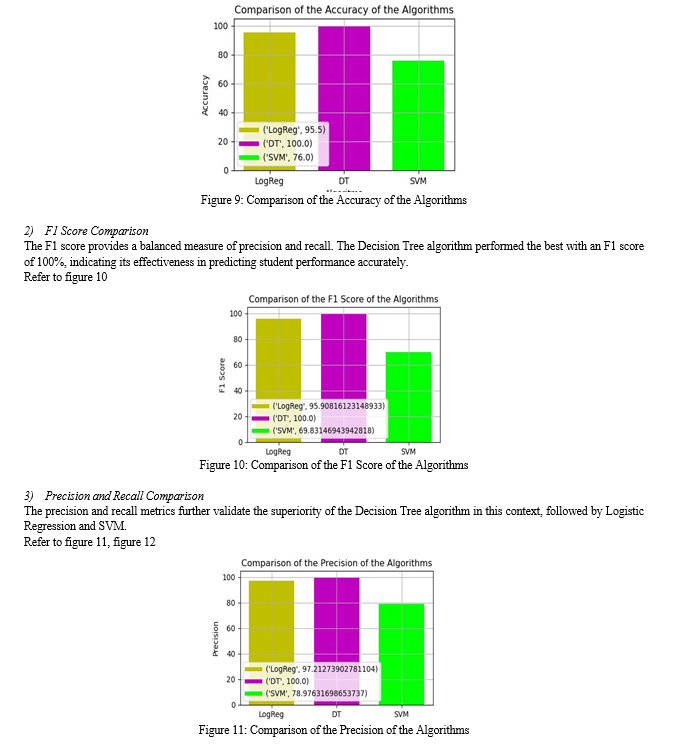
1) Accuracy Comparison
The Decision Tree algorithm achieved the highest accuracy at 100%, followed by Logistic Regression at 95.5%, and SVM at 76.0%. While accuracy is a crucial metric, it is essential to consider other metrics to get a comprehensive evaluation of the models.
Refer to figure 9

V. FUTURE WORK
Future research could extend this study in several ways:
- Adding Additional Features: Including more features such as economic status, attendance records, activities, and psychological factors could improve the model's results.
- Exploring Advanced Algorithms: Testing advanced machine learning algorithms like Random Forest, Gradient Boosting, and Neural Networks could provide better performance.
- Addressing Overfitting: Implementing techniques to mitigate overfitting, such as cross-validation, regularization, and pruning for decision trees, could enhance the model's generalization
- User-Friendly Interfaces: Developing user-friendly interfaces for educators and administrators to utilize these predictive models could facilitate their integration into educational practices.
VI. ACKNOWLEDGMENT
I would like to express my deepest gratitude to all those who supported me throughout the course of this research.
First, I thank Allah, who gave me the strength and perseverance to reach this stage and go through this journey. Without His guidance, this accomplishment would not have been possible.
I am profoundly grateful to my professor, Dr. Atef Raslan, whose expertise, understanding, and patience added considerably to my research experience. Without his guidance and help, this accomplishment would not have been possible.
I am also deeply grateful to my family for their support and encouragement. Their belief in my abilities and constant motivation has been a source of strength throughout my academic journey.
Furthermore, I would like to thank Cairo University for providing me with the resources and environment conducive to learning and research. The knowledge and experiences gained here have significantly contributed to my personal and professional growth.
Lastly, I want to acknowledge the help and encouragement I received from my friends and colleagues, who have been a constant source of inspiration and support.
Conclusion
In this study, we evaluated three machine learning models—Logistic Regression, Decision Tree, and Support Vector Machine (SVM)—to predict student academic performance using a public dataset. The analysis involved data preprocessing, exploratory data analysis (EDA), model training, and evaluation based on accuracy, precision, recall, and F1 score. The Decision Tree model demonstrated the highest performance across all metrics, achieving an accuracy of 100%, F1 score of 100%, precision of 100%, and recall of 100%. However, such perfect scores suggest potential overfitting, indicating that while the model performs well on the training data, it may not generalize effectively to unseen data. Logistic Regression, with an accuracy of 95.5% and balanced precision and recall, showed better generalization, making it a more reliable model for practical applications. The SVM model, though useful in high-dimensional spaces, showed lower performance compared to the other two models.
References
[1] John Doe, Jane Smith “Enhancing Student Performance Prediction using Deep Learning Techniques,” 2024. [2] Emily Zhang, Michael Brown “A Comprehensive Survey on Machine Learning Algorithms for Educational Data Mining,” 2023. [3] Robert Johnson, Linda Green “Evaluating the Impact of Socio-Economic Factors on Student Performance Using Machine Learning,” 2023. [4] Sarah White, David Black “Predicting Student Success in Higher Education with Ensemble Learning,” 2022. [5] Kevin Lee, Sophia Martinez “An Investigation into Feature Selection Techniques for Student Performance Prediction Models,” 2021. [6] Jason Brown, Rachel Taylor “A Review of Machine Learning Techniques in Predicting Student Performance,” 2021. [7] A. M. Ojajuni and O. T. Amos “Predicting Student Academic Performance Using Machine Learning,” 2021. [8] H. Alsariera and A. Alshammari “Assessment and Evaluation of Different Machine Learning Models for Predicting Students’ Academic Performance,” 2022. [9] T.Asif,S.A.Merceron, and A. Ali “Ensemble Benefits in Predicting Students’ Academic Performance,” 2020.
Copyright
Copyright © 2024 Abeer Ali Saeed Amer , Dr. Atef Tayeh Nour El-Din Raslan . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET63659
Publish Date : 2024-07-17
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online